

츄르사려고 코딩하는 코집사입니다.
파이썬 크롤링을 이용하여 네이버 주식 매매 동향 데이터를 가져와 간단한 데이터 분석을 해보려고 합니다.
네이버의 주소는 아래의 Url입니다.
finance.naver.com/sise/sise_trans_style.nhn
1. 라이브러리 불러오기
import requests #크롤링을 위한 라이브러리
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from io import BytesIO
from datetime import datetime # 오늘 날짜 불러오는 라이브러리1) requests
- 크롤링을 위한 라이브러리
2. plt 라이브러리를 이용한 그래프에서 글자 깨짐 방지
#plot 한글 깨짐
plt.rc('font', family='Malgun Gothic')
3. 코드를 돌리는 기준으로 오늘 년도와 달, 일 가져오기
#코드를 돌리는 기준으로 오늘 년도와 달, 일 가져오기
Today = str(datetime.today().year) + str(datetime.today().month) + str(datetime.today().day)
Today = int(Today) #20201128 이렇게 저장이 된다.1) 위의 라이브러리 불러오기에서 from datetime import datetime은 여기서 사용됩니다.
2) datetime.today()를 사용하면 아래처럼 출력 결과가 나옵니다. 그래서, 저는 str로 변환하여 합쳐 준 뒤, 다시 int형으로 변환하였습니다.

3) 이 Today라는 데이터는 아래에서 크롤링할 때 format 형식에서 사용할 예정입니다.
4. 초기 셋팅 해주기
1) 초기 셋팅은 네이버 주식 매매 동향에서 제공하는 아래의 테이블에 맞게 데이터프레임을 설정합니다.
2) 2020년 11월 28일 기준 총 페이지의 수는 394페이지까지 존재합니다.
3) requests.get()함수를 사용하여 url에 접속하고, 긁어와 html 기반 데이터 프레임을 생성합니다.

#page 수 2020년 11월 28일 기준 394페이지까지 존재
Page = 1
#코스피 투자자별 매매 동향 URL
Url = "https://finance.naver.com/sise/investorDealTrendDay.nhn?bizdate={0}&sosok=&page={1}".format(Today,page)
#requests 라이브러리를 사용하여 url 접속
Req = requests.get(url)
#url에 있는 html을 긁어와 html에 저장
Html = BytesIO(req.content)
#코스피라는 변수에 html기반 데이터 프레임 생성
코스피_최종 = pd.read_html(html)[0]4) 결과
- 데이터프레임에서 columns는 2개의 레벨이 존재하고 있습니다.
- 중간중간 NaN이 보이는데, 장이 열리지 않는 날이 존재합니다.
- NaN은 제거할 예정입니다.

5. 크롤링 시작
1) 1 페이지부터 394 페이지까지 반복문을 통한 크롤링을 시작합니다.
2) 아까 코드를 돌리는 날짜를 기준으로 Today에 저장하여 format 형식을 통해 크롤링을 합니다.
3) 마지막에 페이지들의 데이터 프레임을 기존 데이터 프레임과 합쳐줍니다.
#무선연결 기준 1분 30초 정도 소요
for Page in range(1,395) :
#코스피 투자자별 매매 동향 URL
Url = "https://finance.naver.com/sise/investorDealTrendDay.nhn?bizdate={0}&sosok=&page={1}".format(Today, page)
#requests 라이브러리를 사용하여 url 접속
Req = requests.get(url)
#url에 있는 html을 긁어와 html에 저장
Html = BytesIO(req.content)
#코스피라는 변수에 html기반 데이터 프레임 생성
코스피 = pd.read_html(html)[0]
#코스피_최종 데이터 프레임과 코스피 데이터 프레임 합치기
코스피_최종 = pd.concat([코스피_최종, 코스피])
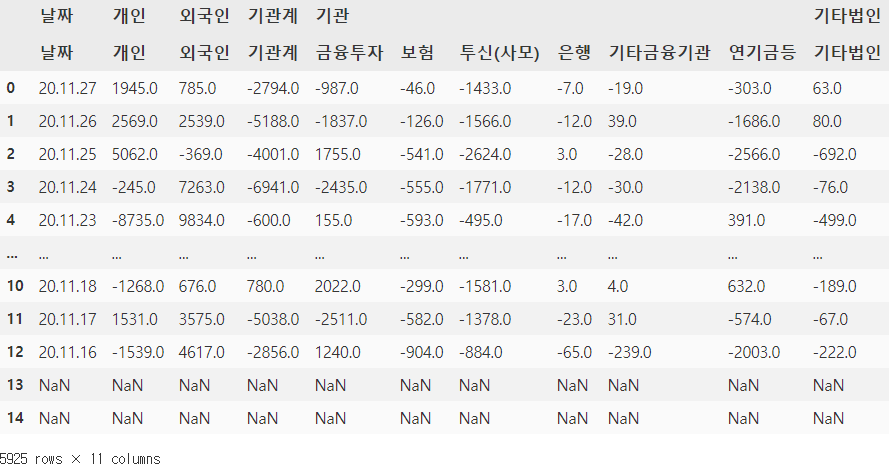
4) 결과
- 5925 X 11 데이터 프레임이 생성되었습니다.
- 여전히 2개 레벨의 columns와 NaN이 존재합니다.
6. NA 제거
1) 코스피_최종 데이터 프레임에서 NA를 제거합니다.
2) 제거된 NA의 행 인덱스는 비어 보기 좋게 인덱스를 재정렬 합니다.
#코스피_최종 데이터프레임에서 NA 제거
코스피_최종 = 코스피_최종.dropna()
#코스피_최종 데이터 프레임에서 NA 제거한 행 인덱스가 비어 있기 때문에 재정렬
코스피_최종 = 코스피_최종.reset_index(drop=True)3) 결과
- 5925개의 행에서 1975개의 행이 삭제 되어 3950개의 행으로 줄었습니다.

7. 코스피_최종 데이터 프레임에서 columns의 레벨 낮추기
1) columns가 2줄로 되어 있어 보기 좋게 droplevel()을 통해 레벨을 다운시켜 줍니다.
#위의 코스피_최종 데이터프레임에서 columns가 중복되는 경우가 있어 droplevel()을 통해 레벨 다운
코스피_최종.columns = 코스피_최종.columns.droplevel()2) 결과

8. 변수간의 상관관계 보기
#코스피_최종 데이터에서 각 변수간의 상관관계
코스피_상관관계 = 코스피_최종.corr(method='pearson')
코스피_상관관계
#상관관계 히트맵
plt.subplots(figsize=(18,15))
sns.heatmap(코스피_상관관계, vmax=1,square=True)1) 결과
- 개인과 외국인 변수간의 상관관계가 제일 높은 것으로 나타나고 있습니다.(음의 상관관계)
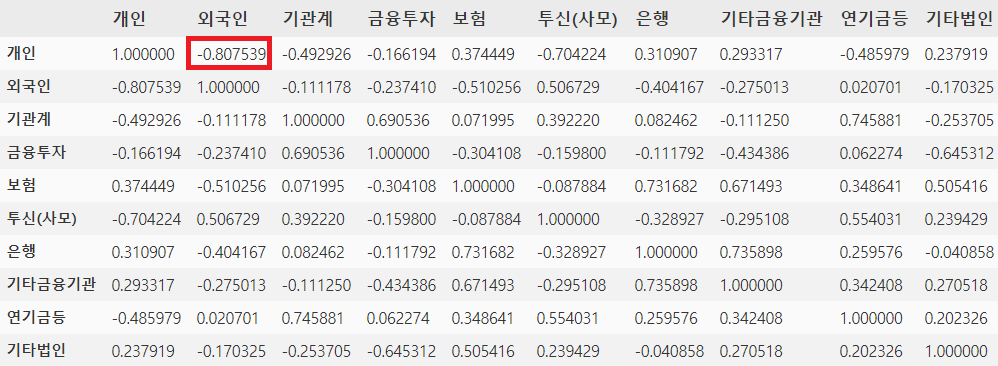
2) 히트맵

9. seaborn 라이브러리를 이용한 그래프
1) 상관관계가 제일 높았던 개인과 외국인의 그래프
- regplot은 산점도와 라인 그래프를 합쳐서 보여주는 그래프
sns.regplot(x='개인', y='외국인', data=코스피_최종)
2) 결과

10. 전체 데이터
import requests
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from io import BytesIO
from datetime import datetime # 오늘 날짜 불러오는 라이브러리
#plot 한글 깨짐
plt.rc('font', family='Malgun Gothic')
#코드를 돌리는 기준으로 오늘 년도와 달, 일 가져오기
Today = str(datetime.today().year) + str(datetime.today().month) + str(datetime.today().day)
Today = int(Today) #20201128 이렇게 저장이 된다.
#page 수 2020년 11월 28일 기준 394페이지까지 존재
Page = 1
#코스피 투자자별 매매 동향 URL
Url = "https://finance.naver.com/sise/investorDealTrendDay.nhn?bizdate={0}&sosok=&page={1}".format(Today,page)
#requests 라이브러리를 사용하여 url 접속
Req = requests.get(url)
#url에 있는 html을 긁어와 html에 저장
Html = BytesIO(req.content)
#코스피라는 변수에 html기반 데이터 프레임 생성
코스피_최종 = pd.read_html(html)[0]
#장이 열리지 않는 날은 NaN 처리 -> 데이터프레임 concat하고 삭제 예정
코스피_최종
#무선연결 기준 1분 30초 정도 소요
for Page in range(1,395) :
#코스피 투자자별 매매 동향 URL
Url = "https://finance.naver.com/sise/investorDealTrendDay.nhn?bizdate={0}&sosok=&page={1}".format(Today, page)
#requests 라이브러리를 사용하여 url 접속
Req = requests.get(url)
#url에 있는 html을 긁어와 html에 저장
Html = BytesIO(req.content)
#코스피라는 변수에 html기반 데이터 프레임 생성
코스피 = pd.read_html(html)[0]
#코스피_최종 데이터 프레임과 코스피 데이터 프레임 합치기
코스피_최종 = pd.concat([코스피_최종, 코스피])
코스피_최종
#코스피_최종 데이터프레임에서 NA 제거
코스피_최종 = 코스피_최종.dropna()
#코스피_최종 데이터 프레임에서 NA 제거한 행 인덱스가 비어 있기 때문에 재정렬
코스피_최종 = 코스피_최종.reset_index(drop=True)
코스피_최종
#위의 코스피_최종 데이터프레임에서 columns가 중복되는 경우가 있어 droplevel()을 통해 레벨 다운
코스피_최종.columns = 코스피_최종.columns.droplevel()
코스피_최종
#코스피_최종 데이터에서 각 변수간의 상관관계
코스피_상관관계 = 코스피_최종.corr(method='pearson')
코스피_상관관계
#상관관계 히트맵
plt.subplots(figsize=(18,15))
sns.heatmap(코스피_상관관계, vmax=1,square=True)
sns.regplot(x='개인', y='외국인', data=코스피_최종)'빅데이터 분석 > 빅데이터 분석 학습' 카테고리의 다른 글
| [데이터 크롤링] 서울 카페 경위도 크롤링하기 with Python (0) | 2021.05.25 |
|---|---|
| [Python 크롤링] 네이버 뉴스 크롤링하기 with Python (0) | 2021.05.24 |
| [데이터 크롤링] 카카오 api를 활용한 서울 편의점 경위도 크롤링하기 with Python (62) | 2021.05.21 |
| 엔트로피(Entropy) 머신러닝 통계 - 의사결정나무(Decision Tree) (0) | 2020.12.17 |
| 인포그래픽과 빅데이터 시각화의 차이 (0) | 2020.09.09 |
| 통계 일변량 분석 기초 (0) | 2020.08.27 |
| 빅데이터 분석과 데이터베이스 이론 (0) | 2020.08.25 |
| 빅데이터의 이해 및 활용(빅데이터의 저장) (0) | 2019.06.09 |








최근댓글