

츄르사려고 코딩하는 코집사입니다.
1. 주제
- 주차장을 활용한 거리에 따른 로컬푸드 드라이브스루 입지 선정
2. 로컬푸드란?
- 반경 50km 이내 지역에서 생산되는 지역 생산 농식품
- 소비자와 농가의 상생을 통해 서로 이득을 얻을 수 있는 장점
- 완주군에서는 2008년 로컬푸드정책을 시행하여 2012년 첫 로컬푸드 직매장 오픈
- 지금까지도 로컬푸드 시장은 성장하고 있음

3. 기존 매장과 로컬푸드 매장의 차이
- 기존 매장에서는 농식품을 생산하여 소비자에게 전달까지 평균 3 ~ 6일 소요
- 로컬푸드 매장은 기존 매장과 달리 평균 0.5 ~ 1일 소요
4. 로컬푸드 직매장 시장 현황
- 2013년부터 연마다 로컬푸드 직매장의 수는 증가
- 2019년에는 2013년보다 370개의 매장 증가
- 매장 수가 증가함에 따라 판매액 또한 증가
5. 드라이브스루 현황
- 맥도날드 매장은 드라이브스루를 접목하여 매출을 40%이상 증가시켰음
- 전라북도청 주차장에서는 전북 로컬푸드 드라이브스루 행사를 진행하여 4시간만에 완판하는 성공적인 사례를 만듦
6. 로컬푸드 직매장 방문 설문조사
- 300명을 대상으로 로컬푸드 이용객에 대한 설문 조사 실시
- 약 63.3%의 방문객은 근처를 지나가다가 로컬푸드 직매장 방문
- 그 중, 거주지 간 거리가 가깝고, 자가용을 타고 로컬푸드 직매장 방문
7. 주제 선정
- 따라서, '접근성이 높으면 로컬푸드 직매장에 많이 방문할 것이고, 직매장을 많이 방문함에 따라 매출량 또한 증가할 것이다.' 라는 가설 설정
8. 분석 프로세스

9. 데이터 수집
- 총 10개의 데이터 수집

10. 데이터 전처리
1) 데이터 칼럼변수
- 지점, 면적, 방문객수, 인구, 유동인구수, 방문빈도수, 도로 혼잡도, 차선수, 블로그수, 생산인구수, 주변 대형 마트, 차량수, 매출
2) 의미있는 칼럼변수 생성 : 방문효율
- 방문효율 = 방문객수 / 유동인구수
- 방문객수를 유동인구수로 나눠 방문 효율의 수치적 데이터 생성
3) 의미있는 칼럼변수 생성 : 접근지수
- 접근지수 = 인구 * 방문효율
- 지역의 인구에 방문효율을 곱하여 잠재 인구 수치 데이터 생성

4) 결측치 처리
- 데이터 칼럼변수에서 총 7개의 결측치 변수 확인
- 결측치를 제거하지 않고, 평균값으로 대체하여 처리
- 데이터가 부족하여 결측치를 제거할 경우 예측에 어려움을 느껴 매출을 예측할 수 있는 머신러닝 모델 설계

5) 이상치(Outlier) 처리
- 데이터 칼럼변수에서 총 5개의 이상치 변수 확인
- 도로혼잡도와 면적, 매출의 Outlier는 유의미하지 않아 이상치 제거
- 블로그수와 접근지수의 Outlier는 유의미하다고 판단되어 이상치를 제거하지 않고 유지


11. 데이터 분석
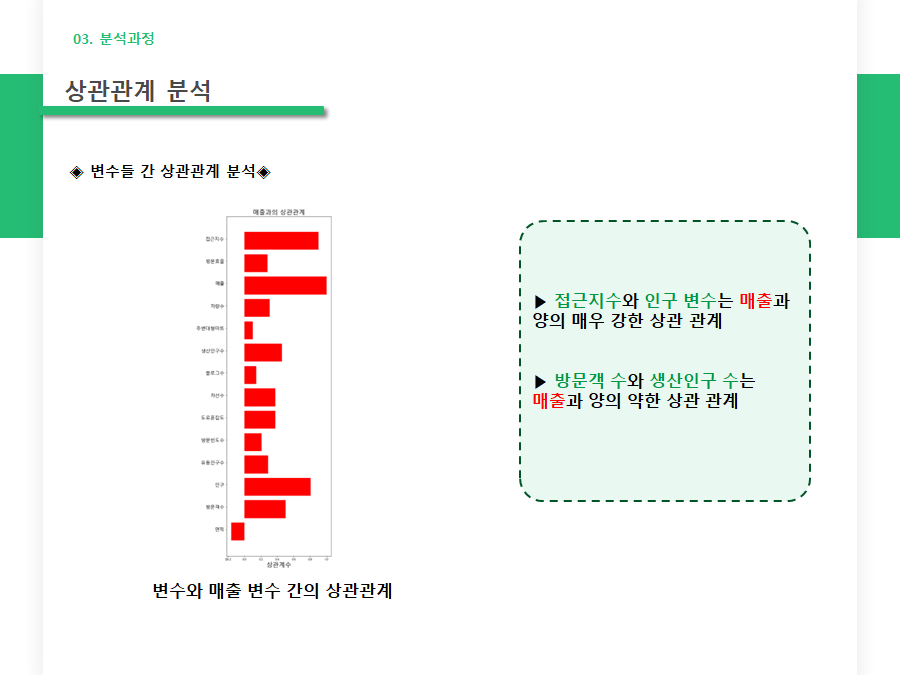
1) 상관관계 분석
- 인구는 접근지수와 매출과의 강한 상관 관계
- 접근지수는 매출과의 강한 상관 관계
- 매출이라는 반응변수와 각 설명변수간의 상관 관계 분석 결과 접근지수와 인구, 방문객 수, 생산인구 수는 매출과 상관 관계가 있음

2) 선형회귀분석
- 반응변수인 매출과 각 설명변수 간의 선형회귀분석 결과 그나마 인구와 접근지수는 매출과의 선형성을 가지고 있음
- 선형회귀분석의 R-squared 값 확인 결과 0.563으로 다소 낮은 설명력을 갖고 있었음

3) 다중선형회귀분석
- 다중회귀분석 후진제거법을 통해 각 변수들간의 회귀분석 결과 방문객 수, 인구, 방문효율, 접근지수를 설명변수로 설정하였음
- 그 결과, R-squared 값은 0.925로 적정 설명력을 가지고 있음

4) 머신러닝 모델 설계
- XGBoost, Random Forest, Lasso, Ridge, Decision Tree, Ada Boosting 총 6개의 머신러닝 모델 구축
- 6개의 머신러닝 모델 중 가장 정확도가 높은 모델은 XGBoost
- 88.7% 정확도를 가진 XGBoost를 이용하여 매출 예측

5) QGIS를 이용한 최적 입지 선정
- 전라북도에 위치한 로컬푸드 직매장을 노란 Circle로 Mapping


- 매출과 접근성 상위매장을 QGIS에 Mapping 하고, 로컬푸드 드라이브 스루로 사용하기 위한 주차장을 파란 Circle로 Mapping


- 주차 구획수가 100대 이상인 주차장 필터링
- 전라북도청 주차장에서 성공적으로 마무리한 로컬푸드 드라이브 스루 성공 사례 참고(100대 이상의 주차장에서 실시)


- 완산구에 접근성과 매출 상위 매장이 많아 완산구 선정
- 그 중, 접근성과 매출 1위인 효자점 기준 위치 선정 시작


- 접근성과 매출 1위인 효자점을 기준으로 거리가 가장 가까운 곳 3곳 선정
- 1위 홍산라이브 광장
- 2위 전주비보이 광장
- 3위 전라북도청 주차장

12. 분석 결과
- 최적 입지는 전라북도청 주차장, 홍산라이브광장 주차장, 전주비보이광장 주차장
1) 전라북도청 주차장
- 주차구획수 1000대 이상
- 주차장 출입구가 매우 커 진입 용이
- 로컬푸드 드라이브스루 행사 경험 5회 이상


2) 홍산라이브광장 / 전주비보이광장 주차장
- 각 122개, 124개의 주차구획수
- 지하주차장으로 구성


3) 지하주차장의 로컬푸드 드라이브 스루 행사 가능? 불가능?
- 임실 지하주차장에서는 전통시장 5일장 행사 실시
- 이 사례를 인용하여 지하주차장에서도 로컬푸드 드라이브 스루 행사 실시 가능

13. 기대효과
- 언택트를 지향하는 소비자의 편의성 증대 및 심적 부담 완화
- 참여 농가와 소비자의 상생을 통한 효과

14. 소스코드
#라이브러리 불러오기
# pip install pandas, folium, plotly
import pandas as pd
import folium # 지도 불러오기 위한 라이브러리
import matplotlib.pyplot as plt #pie 그래프 라이브러리
import plotly.express as px #버블차트 라이브러리
import seaborn as sns #matplotlib 확장 라이브러리(더 이쁘기 시각화하기 위해)
import matplotlib.font_manager as fm #글자 깨짐을 해결하기 위한 라이브러리
from matplotlib import font_manager, rc #글자 깨짐을 해결하기 위한 라이브러리2
from sklearn import linear_model #선형회귀분석을 위해 sklearn(사이킷런)을 사용하기 위한 라이브러리
import numpy as np
#plot 한글 깨짐
plt.rc('font', family='Malgun Gothic')
#막대그래프 한글 깨짐
font_name = font_manager.FontProperties(fname="c:/Windows/Fonts/malgun.ttf").get_name()
rc('font', family=font_name)
real_data = pd.read_csv('C:/Users/User/Desktop/project/찐찐.csv',encoding="CP949")
real_data
real_data.columns
#필요없는 컬럼변수(년도) 삭제
real_data = real_data.drop('년도',axis=1)
#결측치 확인
total = real_data.isnull().sum().sort_values(ascending=False)
percent = (real_data.isnull().sum()/real_data.isnull().count()).sort_values(ascending=False)
missing_data = pd.concat([total, percent], axis=1, keys=['Total', 'Percent'])
percent_data = percent.head(20)
percent_data.plot(kind="bar", figsize = (8,6), fontsize = 10)
plt.xlabel("", fontsize = 20)
plt.ylabel("", fontsize = 20)
plt.title("Total Missing Value (%)", fontsize = 20)
import missingno as msno
missingdata_df = real_data.columns[real_data.isnull().any()].tolist()
msno.heatmap(real_data[missingdata_df], figsize=(8,6))
plt.title("결측치 변수 간의 상관관계", fontsize = 20)
#결측치 mean으로 대체
data = real_data.fillna(real_data.mean())
#결측치 제거
data = data.dropna()
#data.to_csv('data.csv', encoding="CP949")
data_col = data.columns
data_col = data_col[1:15]
data_col
for i in data_col :
plt.boxplot(data[i])
plt.xlabel(i)
plt.show()
data = data[data['도로혼잡도']>0]
data = data[data['면적']<10000]
data = data[data['매출']>4000000000]
for i in data_col :
plt.boxplot(data[i])
plt.xlabel(i)
plt.show()
data_Y = data['매출']
data_Y
#데이터프레임에 열 추가(방문효율, 접근지수)
data['방문효율'] = data['방문객수'] / data['유동인구수']
data['접근지수'] = data['인구'] * data['방문효율']
data
#boxplot을 사용한 이상치 처리
data_col = data.columns
data_col = data_col[1:15]
for i in data_col :
plt.boxplot(data[i])
plt.xlabel(i)
plt.show()
data = data[data['접근지수']<250000]
data = data[data['블로그수']<4000]
for i in data_col :
plt.boxplot(data[i])
plt.xlabel(i)
plt.show()
#상관관계 분석
data_corr = data.corr(method='pearson')
data_corr
#상관계수에 따른 히트맵
#0.7보다 크면 강한 상관관계
plt.subplots(figsize=(18,15))
sns.heatmap(data_corr, vmax=1,square=True)
data4 = data
data4 = data4.drop(['지점'], axis=1)
data4_corr = data4.corr(method='pearson')
data4_corr
y_corr = list(data4_corr.iloc[11])
y_co = list(data4.columns)
ind = np.arange(len(y_corr))
width = 0.2
fig, ax = plt.subplots(figsize=(6,20))
rects = ax.barh(ind, np.array(y_corr), color='red')
ax.set_yticks(ind+((width)/2.))
ax.set_yticklabels(y_co, rotation='horizontal', size = 15)
ax.set_xlabel("상관계수", size = 20)
ax.set_title("매출과의 상관관계", size = 20)
sns.lmplot(x="접근지수", y="매출", data=data, line_kws={'color':"red"})
sns.lmplot(x="인구", y="매출", data=data, line_kws={'color':"red"})
sns.lmplot(x="면적", y="매출", data=data, line_kws={'color':"red"})
sns.lmplot(x="방문객수", y="매출", data=data, line_kws={'color':"red"})
sns.lmplot(x="인구", y="매출", data=data, line_kws={'color':"red"})
sns.lmplot(x="유동인구수", y="매출", data=data, line_kws={'color':"red"})
sns.lmplot(x="방문빈도수", y="매출", data=data, line_kws={'color':"red"})
sns.lmplot(x="도로혼잡도", y="매출", data=data, line_kws={'color':"red"})
sns.lmplot(x="차선수", y="매출", data=data, line_kws={'color':"red"})
sns.lmplot(x="블로그수", y="매출", data=data, line_kws={'color':"red"})
sns.lmplot(x="생산인구수", y="매출", data=data, line_kws={'color':"red"})
sns.lmplot(x="주변대형마트", y="매출", data=data, line_kws={'color':"red"})
sns.lmplot(x="차량수", y="매출", data=data, line_kws={'color':"red"})
sns.lmplot(x="방문효율", y="매출", data=data, line_kws={'color':"red"})
import statsmodels.api as sm
lm_model = sm.OLS(data['접근지수'].values.reshape(-1,1), data['매출'])
lm_result = lm_model.fit()
print(i, lm_result.summary())
X_data = data[['방문객수','인구','방문효율','접근지수']]
Y_data = data['매출']
linear_regression = linear_model.LinearRegression()
linear_regression.fit(X = pd.DataFrame(X_data), y = Y_data)
prediction = linear_regression.predict(X = pd.DataFrame(X_data))
print('a value = ', linear_regression.intercept_)
print('b value = ', linear_regression.coef_)
YY_data = np.array(Y_data)
fig = plt.figure( figsize = (12, 4))
chart = fig.add_subplot(1,1,1)
chart.plot(YY_data[:88], marker='o', color='blue', label='실제값')
chart.plot(prediction[:88], marker='^', color='red', label='예측값')
chart.set_title('다중회귀분석 예측 결과', size=30)
plt.xlabel('횟수', size=20)
plt.ylabel('매출', size=20)
plt.legend(loc = 'best')
# 위에 블럭 실행
# 적합도 검증 - 잔차
residuals = Y_data-prediction
# 적합도 검증 - 결정계수
SSE = (residuals**2).sum()
SST = ((Y_data-Y_data.mean())**2).sum()
R_squared = 1 - (SSE/SST)
print('R_squared = ', R_squared)
#score 계산
from sklearn.metrics import mean_squared_error
print('score = ', linear_regression.score(X =pd.DataFrame(X_data), y=Y_data))
#매출에 영향을 주는 변수는 방문객수, 인구, 방문효율, 접근지수
#XGBoost
from xgboost import plot_importance
import xgboost as xgb ## XGBoost 불러오기
from xgboost import plot_importance ## Feature Importance를 불러오기 위함
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, accuracy_score, precision_score, recall_score
from sklearn.metrics import confusion_matrix, f1_score, roc_auc_score
from xgboost import XGBRegressor
import math
import warnings
#score 계산
def rmsle(y_pred, y_test) :
assert len(y_test) == len(y_pred)
return np.sqrt(np.mean((np.log(1+y_pred) - np.log(1+y_test))**2))
#매출을 제외한 데이터
data3 = data.drop(['지점','매출'],axis=1)
xgb_data_X = data3
xgb_data_Y = data['매출']
X_train, X_test, Y_train, Y_test = train_test_split(xgb_data_X, xgb_data_Y, test_size = 0.2, random_state = 11)
xgb = XGBRegressor(n_estimators=500, learning_rate = 0.005, max_depth = 5)
xgb.fit(X_train, Y_train)
xgb_pred = xgb.predict(X_test)
score = rmsle(Y_test, xgb_pred)
score
#RandomForestClassifier 클래스를 import
from sklearn.ensemble import RandomForestRegressor
X_train, X_test, Y_train, Y_test = train_test_split(xgb_data_X, xgb_data_Y, test_size = 0.4, random_state = 11)
#Random Forest
rfc = RandomForestRegressor()
rfc.fit(X_train, Y_train)
rfc_pred = rfc.predict(X_test)
rfc_score = rmsle(Y_test, rfc_pred)
rfc_score
#Lasso
from sklearn.linear_model import Lasso
lasso = Lasso(alpha=0.01,max_iter=10000).fit(X_train, Y_train)
lasso_pred = lasso.predict(X_test)
lasso_score = rmsle(Y_test, lasso_pred)
lasso_score
#Ridge
from sklearn.linear_model import Ridge
ridge = Ridge(alpha =0.01).fit(X_train,Y_train)
ridge_pred = ridge.predict(X_test)
ridge_score = rmsle(Y_test, ridge_pred)
ridge_score
#Decision Tree
from sklearn.tree import DecisionTreeRegressor
Decision = DecisionTreeRegressor(max_depth=7)
Decision.fit(X_train,Y_train)
Decision_pred = Decision.predict(X_test)
Decision_score = rmsle(Y_test, Decision_pred)
Decision_score
#ada Boosting
from sklearn.ensemble import AdaBoostRegressor
ada = AdaBoostRegressor()
ada.fit(X_train, Y_train)
ada_pred = ada.predict(X_test)
ada_score = rmsle(Y_test, ada_pred)
ada_score
Model_Name = ['XGBoost','Random Forest','Lasso','Ridge','Decision Tree','ADA Boosting']
Model_Score = [score, rfc_score,lasso_score, ridge_score, Decision_score, ada_score]
plt.figure(figsize = (15,10))
plt.title("머신러닝 모델 정확도", size = 50)
plt.xlabel("모델 이름", size = 35)
plt.ylabel("정확도", size = 35)
plt.xticks(size = 30, rotation=60)
plt.yticks(size = 30)
sns.barplot(Model_Name, Model_Score)
#plt.bar(Model_Name, Model_Score)
residuals.describe()




최근댓글