
반응형

파이썬 셀레늄(Selenium)을 이용한 크롤링하기
1. 셀레늄(Selenium) 설치하기
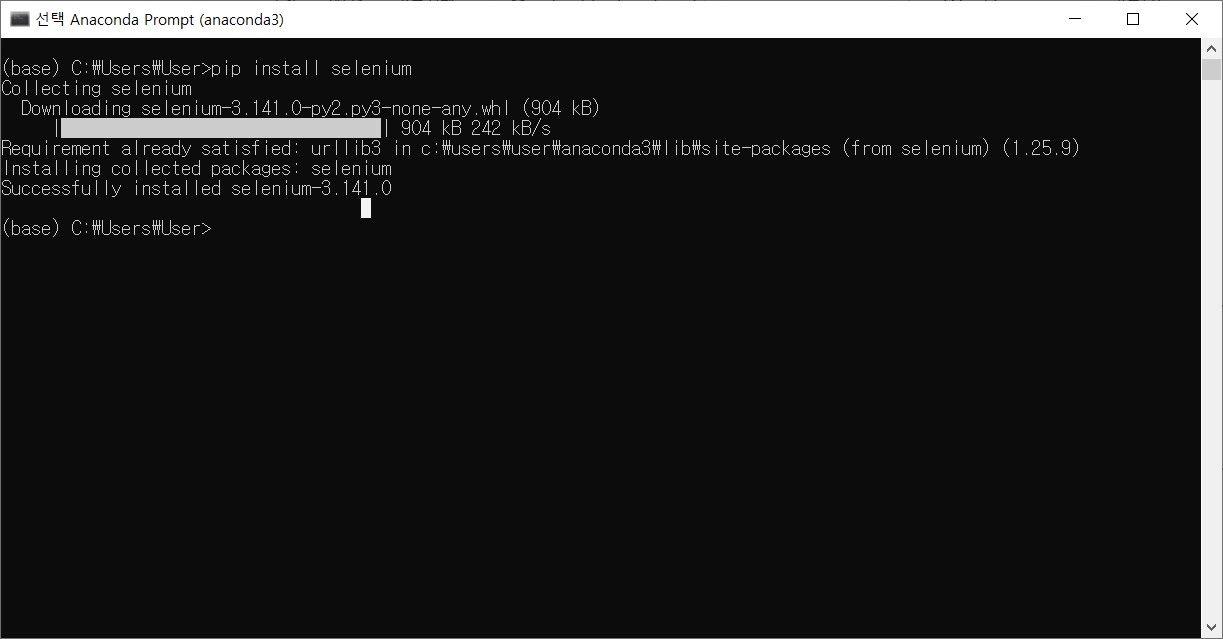
1) anaconda prompt에서 pip install selenium 명령어를 입력하여 설치하기
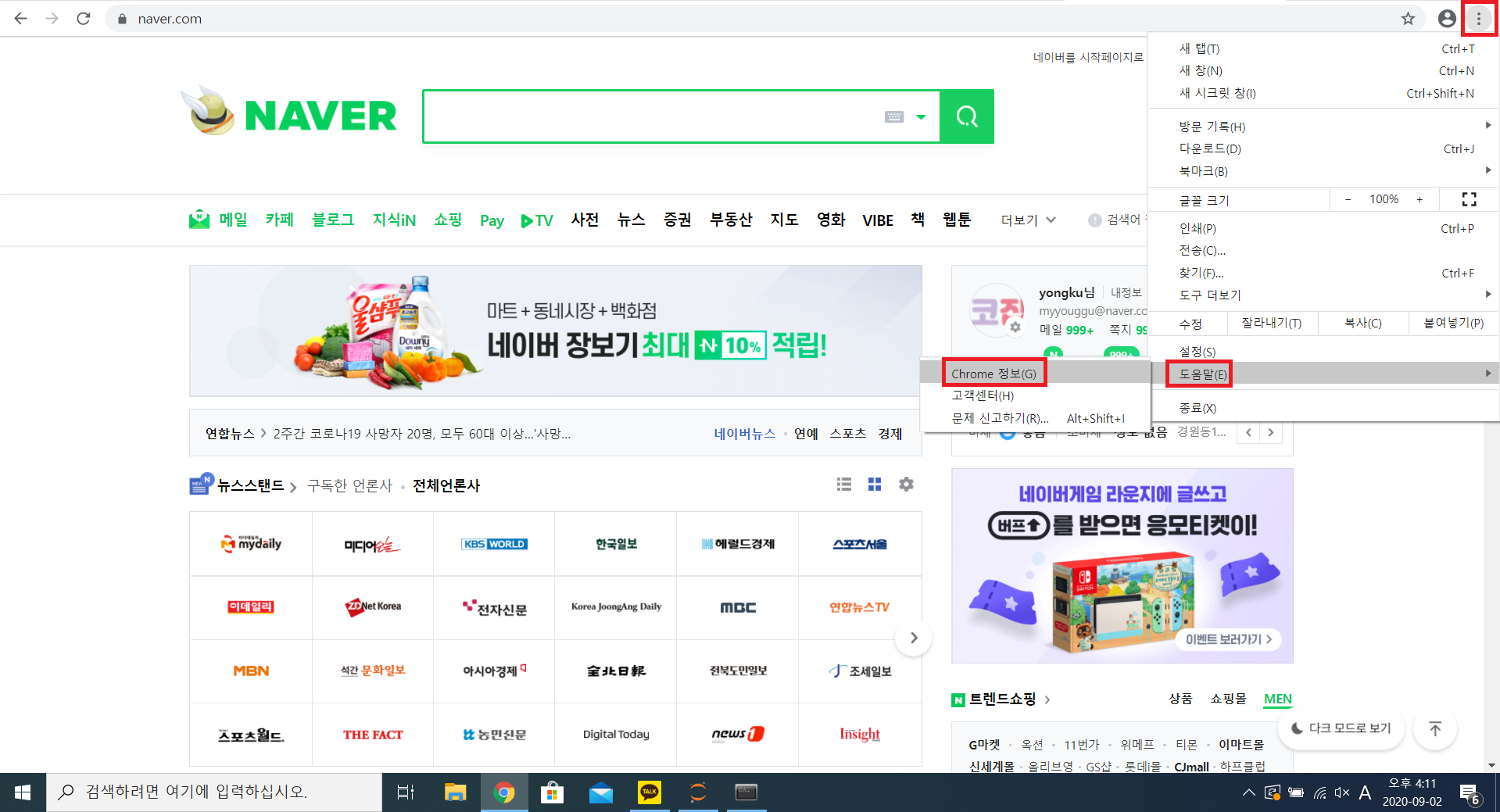
2) 크롬 브라우저 버전 확인하기
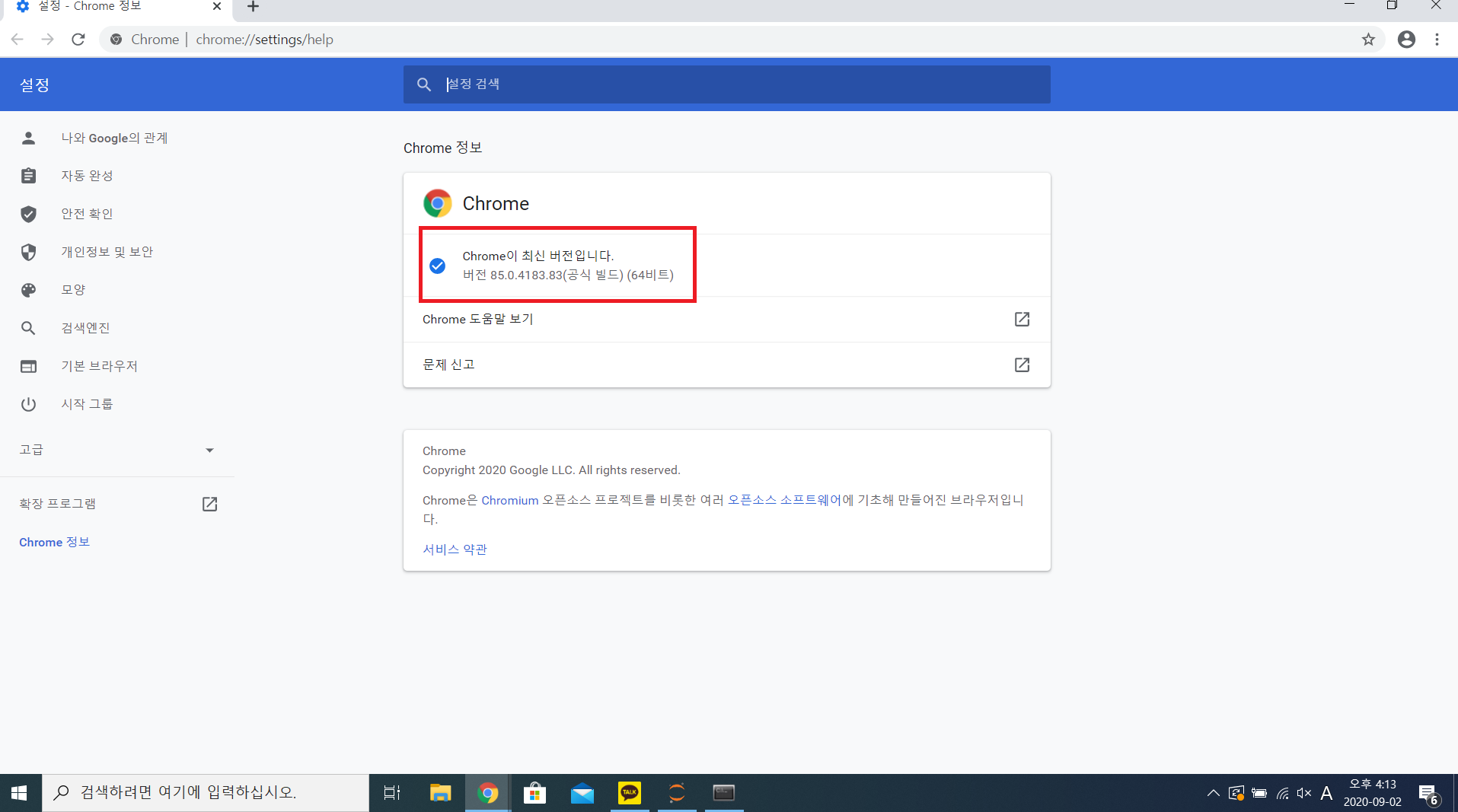
> [메뉴] - [도움말] - [Chrome정보]
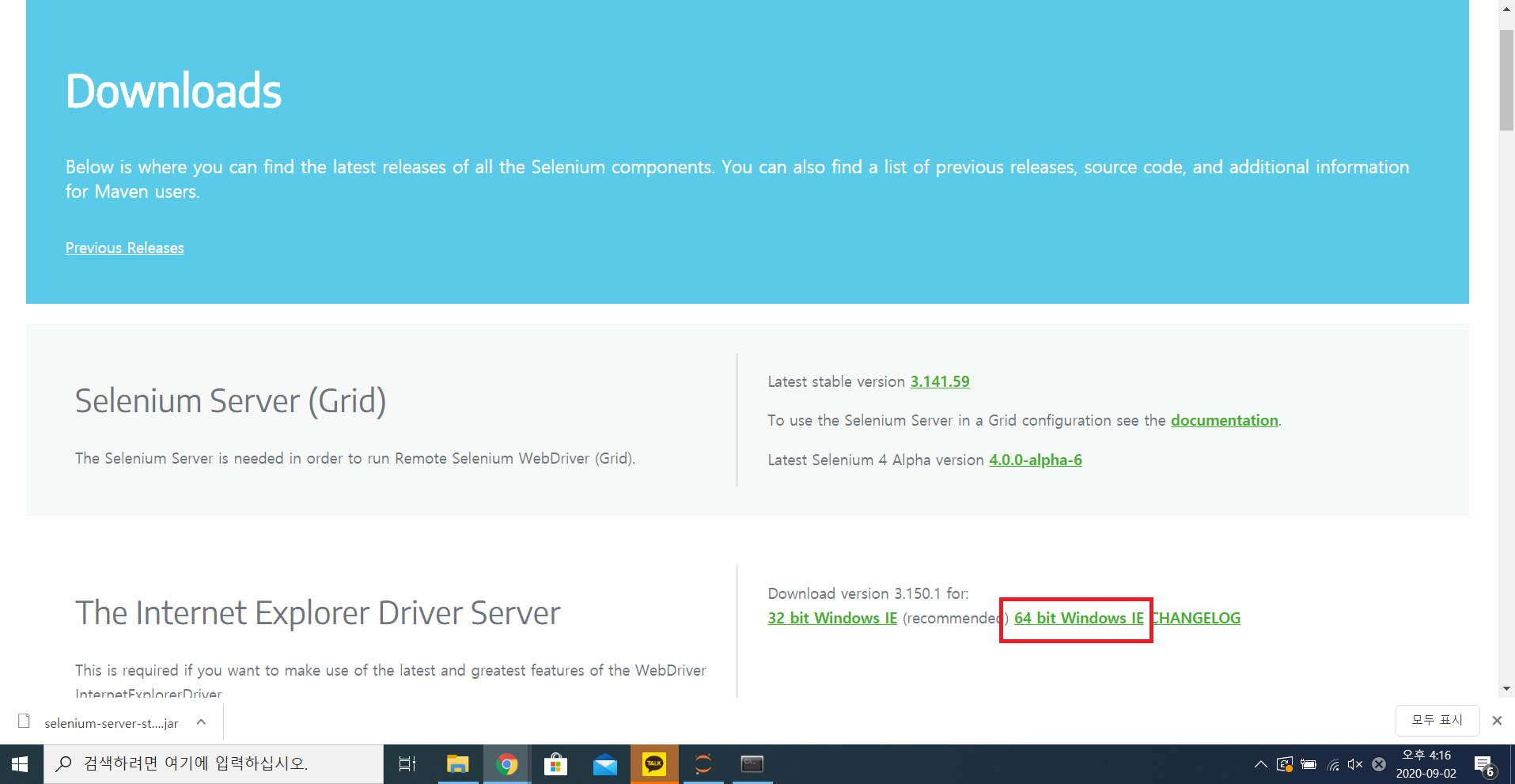
3) Selenium Standalone Server 다운로드하기
> 크롬에서 https://www.selenium.dev/downloads/ 로 들어가서 ipynb 파일 위치에 다운로드하기
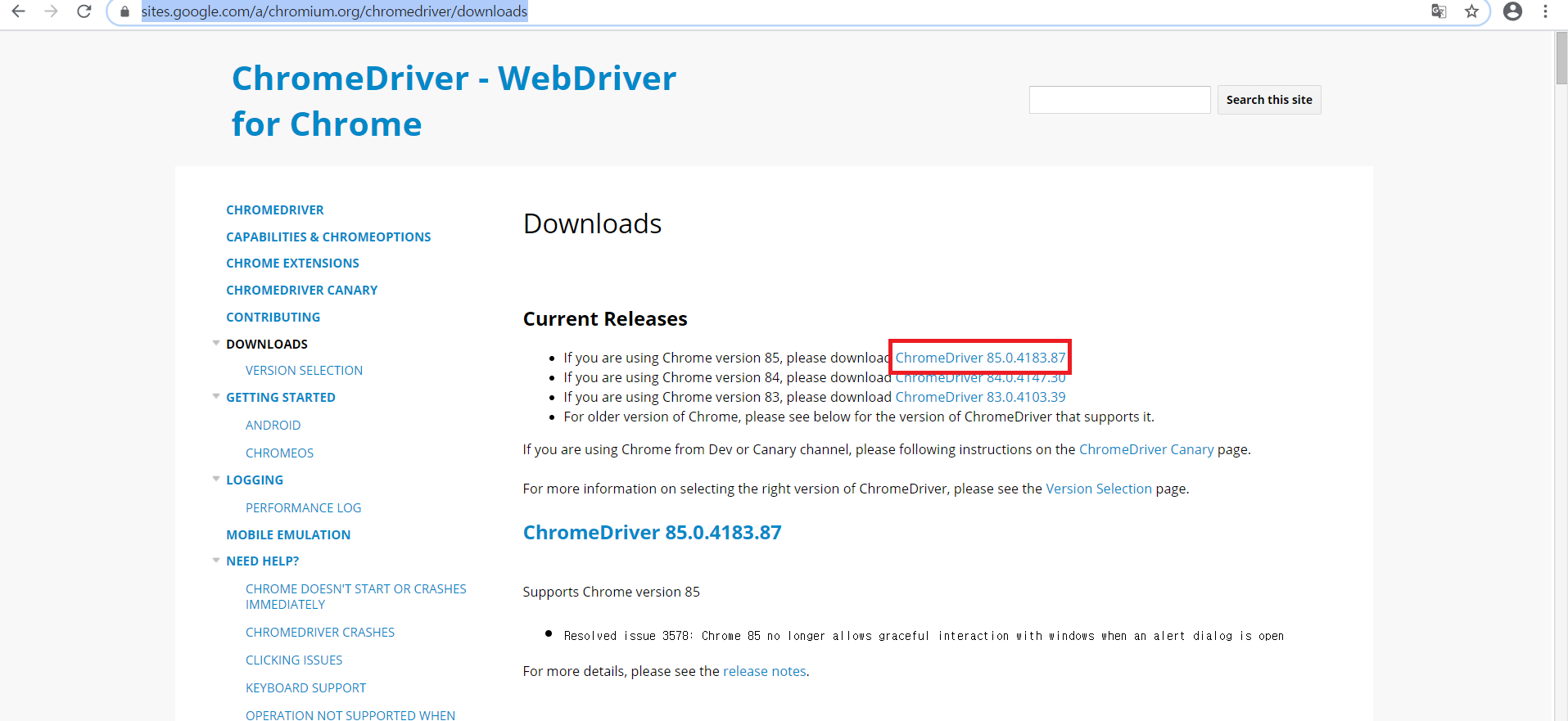
4) 아래의 URL에 들어가 드라이버와 디렉토리 다운로드하고 실행하기
> sites.google.com/a/chromium.org/chromedriver/downloads
> 크롬 버전과 맞게 다운로드하기
from selenium.webdriver import Chrome
import time
import sqlite3
from pandas.io import sql
import os
import pandas as pd
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--start-maximized");
browser = webdriver.Chrome('chromedriver', options=options)
#기동된 브라우저를 통한 URL 접속
browser.get('https://www.data.go.kr/')
browser.implicitly_wait(5)
browser.find_element_by_xpath('//*[@id="header"]/div/div/div/div[2]/div/a[1]').click()
browser.implicitly_wait(5)
browser.find_element_by_xpath('//*[@id="mberId"]').send_keys('bjkim2004')
browser.find_element_by_xpath('//*[@id="pswrd"]').send_keys('TEJeuBlidb^2')
browser.find_element_by_xpath('//*[@id="loginVo"]/div[2]/div[2]/div[2]/div/div[1]/button').click()
browser.implicitly_wait(5)
browser.find_element_by_xpath('//*[@id="M000400_pc"]/a').click()
browser.find_element_by_xpath('//*[@id="M000402_pc"]/a').click()
def db_save(ARTICLE_LIST):
with sqlite3.connect(os.path.join('.','sqliteDB')) as con: # sqlite DB 파일이 존재하지 않는 경우 파일생성
try:
ARTICLE_LIST.to_sql(name = 'ARTICLE_LIST', con = con, index = False, if_exists='append')
#if_exists : {'fail', 'replace', 'append'} default : fail
except Exception as e:
print(str(e))
print(len(ARTICLE_LIST), '건 저장완료..')
trs = browser.find_elements_by_xpath('//*[@id="searchVO"]/div[5]/table/tbody/tr')
df_list = []
for tr in trs:
df = pd.DataFrame({
'NO': [tr.find_element_by_xpath('td[1]').text],
'TITLE': [tr.find_element_by_xpath('td[2]').text],
'IQRY': [tr.find_element_by_xpath('td[3]').text],
'REGDT': [tr.find_element_by_xpath('td[4]').text],
'CHGDT': [tr.find_element_by_xpath('td[5]').text],
})
df_list.append(df)
ARTICLE_LIST = pd.concat(df_list)
db_save(ARTICLE_LIST)
browser.find_element_by_xpath('//*[@id="searchVO"]/div[5]/table/tbody/tr[1]/td[2]/a').click()
browser.implicitly_wait(3)
browser.find_element_by_xpath('//*[@id="recsroomDetail"]/div[2]/div[4]/div/a').click()
time.sleep(10)
browser.quit()
from selenium.webdriver import Chrome
import time
import sqlite3
from pandas.io import sql
import os
import pandas as pd
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--disable-gpu')
options.add_argument('--window-size=1280x1024')
browser = webdriver.Chrome('chromedriver', options=options)
browser.get('https://www.data.go.kr/')
browser.implicitly_wait(5)
browser.find_element_by_xpath('//*[@id="header"]/div/div/div/div[2]/div/a[1]').click()
browser.implicitly_wait(5)
browser.find_element_by_xpath('//*[@id="mberId"]').send_keys('bjkim2004')
browser.find_element_by_xpath('//*[@id="pswrd"]').send_keys('TEJeuBlidb^2')
browser.find_element_by_xpath('//*[@id="loginVo"]/div[2]/div[2]/div[2]/div/div[1]/button').click()
browser.implicitly_wait(5)
browser.find_element_by_xpath('//*[@id="M000400_pc"]/a').click()
browser.find_element_by_xpath('//*[@id="M000402_pc"]/a').click()
def db_save(ARTICLE_LIST):
with sqlite3.connect(os.path.join('.','sqliteDB')) as con: # sqlite DB 파일이 존재하지 않는 경우 파일생성
try:
ARTICLE_LIST.to_sql(name = 'ARTICLE_LIST', con = con, index = False, if_exists='append')
#if_exists : {'fail', 'replace', 'append'} default : fail
except Exception as e:
print(str(e))
print(len(ARTICLE_LIST), '건 저장완료..')
trs = browser.find_elements_by_xpath('//*[@id="searchVO"]/div[5]/table/tbody/tr')
df_list = []
for tr in trs:
df = pd.DataFrame({
'NO': [tr.find_element_by_xpath('td[1]').text],
'TITLE': [tr.find_element_by_xpath('td[2]').text],
'IQRY': [tr.find_element_by_xpath('td[3]').text],
'REGDT': [tr.find_element_by_xpath('td[4]').text],
'CHGDT': [tr.find_element_by_xpath('td[5]').text],
})
df_list.append(df)
ARTICLE_LIST = pd.concat(df_list)
db_save(ARTICLE_LIST)
browser.find_element_by_xpath('//*[@id="recsroomDetail"]/div[2]/div[4]/div/a').click()
time.sleep(10)
browser.quit()반응형
'Language > Python' 카테고리의 다른 글
| 파이썬 다중 선형 회귀 분석 시각화(Multiple Regression Analysis) (10) | 2020.09.24 |
|---|---|
| 'cp949' codec can't decode byte 0xee in position 15: illegal multibyte sequence (0) | 2020.09.13 |
| 파이썬 데이터프레임 결합하기(concat) (0) | 2020.09.10 |
| 파이썬 folium 라이브러리 예제 (0) | 2020.09.10 |
| 파이썬 다음 뉴스 웹 크롤링하기 (0) | 2020.09.02 |
| 파이썬 퍼머 링크 목록 추출하기 (2) | 2020.09.02 |
| 파이썬 SQLite3 DBMS로 저장하기 (0) | 2020.09.01 |
| 파이썬 XML을 이용하여 기상청 데이터 스크래핑하기 (0) | 2020.09.01 |








최근댓글