AWS 환경 및 서비스를 구축하면서 지금까지 총 4단계를 거쳐서 왔다.
원래 AWS ECR 구축을 했으면 이미지로 컨테이너를 생성하여 ECS까지 넣어봐야 하는데, 먼저 DB에서 SQL을 사용하여 로그 또는 데이터 확인을 하는 것처럼 AWS S3에 파일을 넣어 놓고, SQL을 사용하여 조회할 수 있는 AWS Athena 서비스를 먼저 구축해서 테스트를 하려고 한다.
먼저, AWS Athena 서비스를 구축하는 단계다.
AWS Athena
Amazon Athena는 표준 SQL을 사용하여 Amazon S3 및 기타 연동 데이터 원본의 데이터를 쉽게 분석할 수 있는 대화형 쿼리 서비스입니다.
라고 공식 홈페이지에 설명이 되어 있다. 즉, AWS S3에 파일로 떨어진 데이터를 SQL을 사용하여 조회를 할 수 있는 대화형 쿼리 서비스다.
로그를 관리하기 위해 AWS RDS 서비스에 DB를 올리자고 하니 비용이 많이 들어 어려워서 조금 더 값싸게 조회할 수 있는 방법으로 AWS S3에 AWS Athena를 사용하곤 한다. 우리가 흔히, csv, tsv, txt 등의 DB에서 데이터를 추출할 때 사용되는 파일 확장자도 S3에 두면 Athena가 바로 스캔하여 RDBMS 형태로 테이블이 만들어 진다.
Athena의 경우에는 SQL 쿼리문을 실행을 한 경우에 그 부분에 대해서만 비용이 발생한다.
Athena의 비용은 쿼리문을 실행할 때 얼마나 많은 데이터를 가져오냐에 따라 비용이 크게 발생한다.
공식 홈페이지의 글에 따르면, Athena의 비용은 S3에서 스캔하는 데이터 1TB당 5달러라고 한다.
1. AWS Console에 접속해서 aws athena를 검색하면 서비스에 Athena가 나온다.
> Athena는 서버리스 대화형 분석 서비스다.
2. AWS Athena의 주요 기능은 SQL 쿼리, 노트북, 데이터 소스, 워크플로, Workgroups이 있는데 뭔지 모르니 그냥 클릭하여 접속한다.
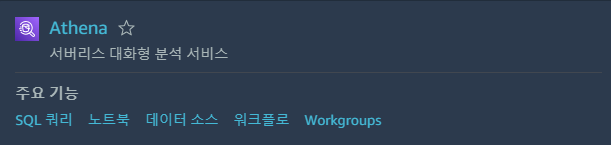
3. AWS의 작동 방식은 S3에 파일을 넣고 Athena의 쿼리 편집기를 사용하여 SQL 작성하면 된다.
4. 그러면 AWS S3에 데이터를 넣으면 되는데, S3로 가서 버킷을 클릭한다.
5. 버킷을 클릭하면 객체를 업로드할 수 있는데 업로드 버튼을 클릭한다.

6. 업로드 화면으로 가면 아래와 같이 파일 및 폴더를 추가할 수 있는데, 파일 추가를 하여 업로드를 한다.
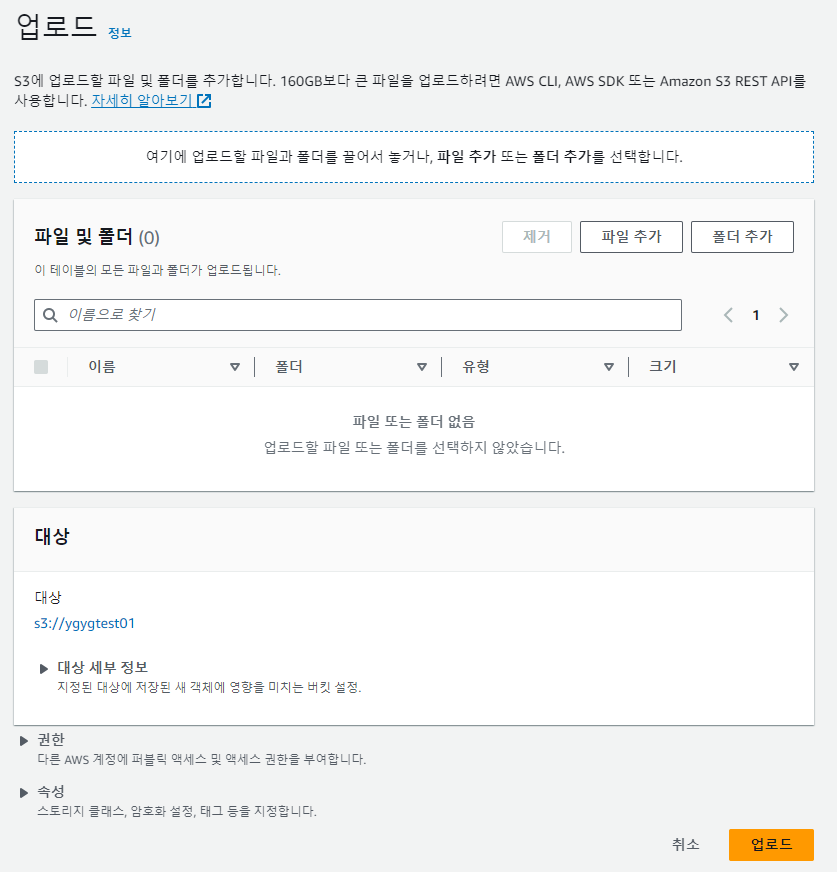
7. TEST.csv라는 파일을 업로드 했는데, 엑셀로 GRADE, AGE, NAME 총 3가지 컬럼을 가진 csv파일을 업로드 했다.
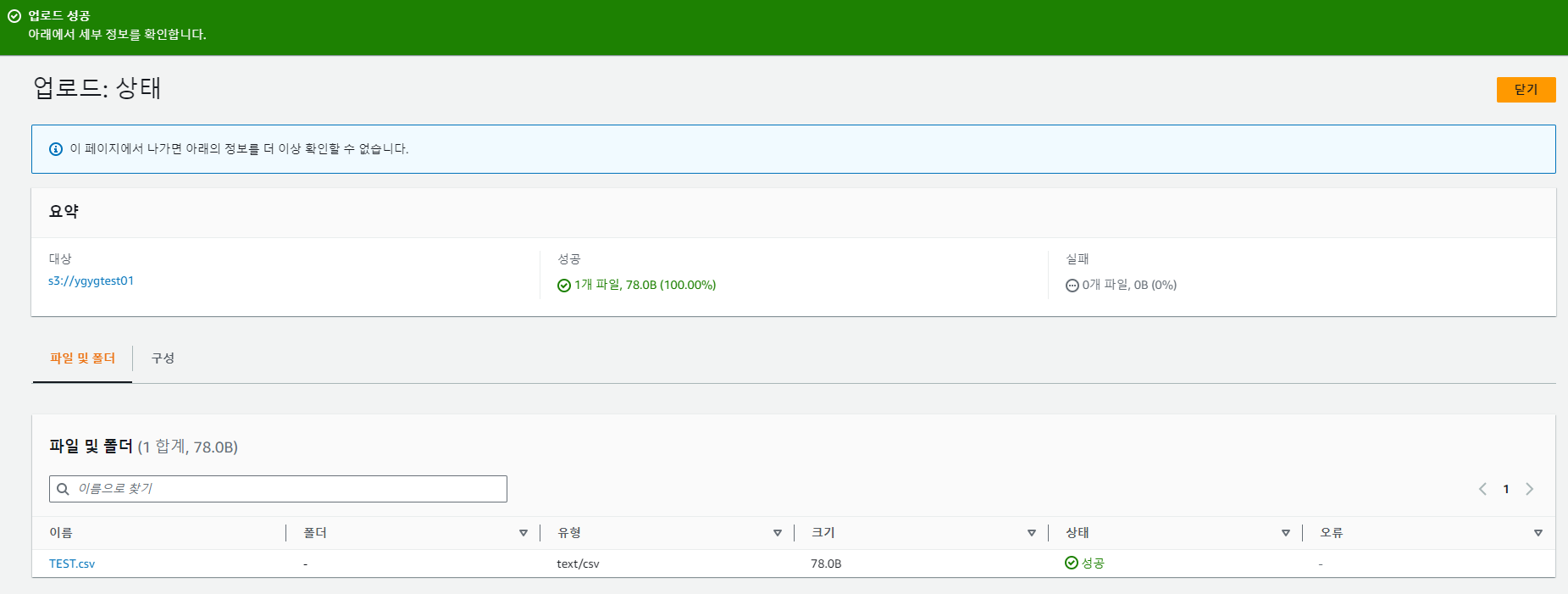
8. 업로드를 하면 TEST.csv 파일 1개가 업로드 성공했다고 나오게 된다.
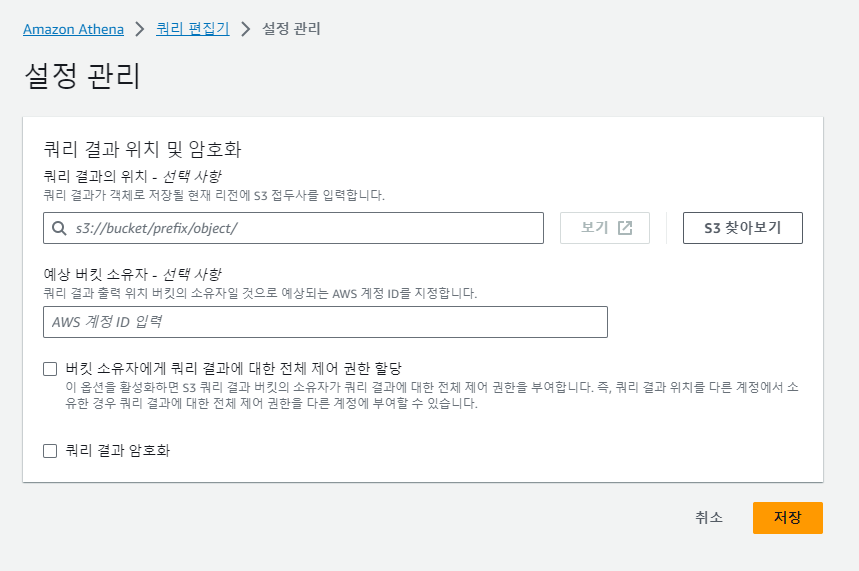
9. 업로드를 성공했으면 편집기로 돌아가서 우측 상단에 설정 편집을 클릭한다.
> 버킷에 저장되어 있는 데이터 경로를 잡아줘야 한다.

10. 설정 관리 화면에서 쿼리를 실행했을 때 나오는 결과를 어디에 저장할 것인지에 대한 위치를 설정할 수 있다.
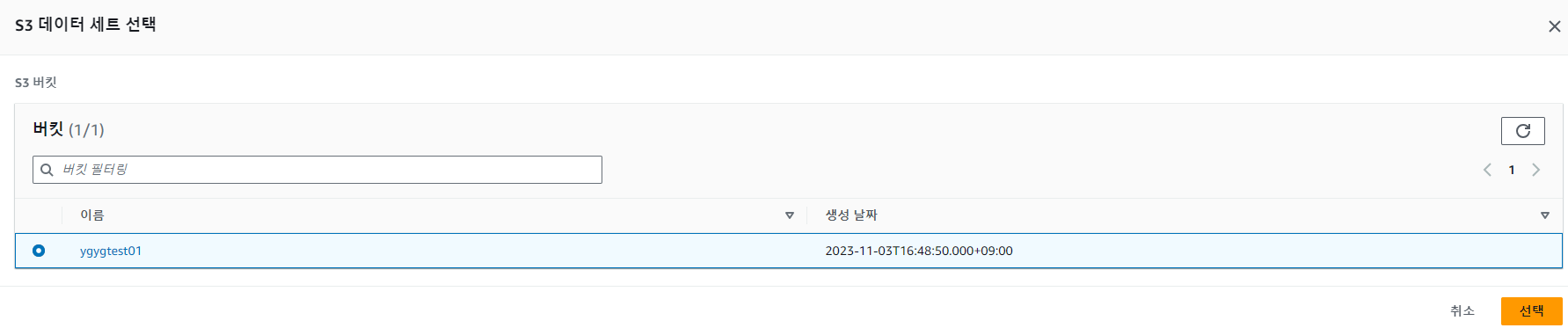
11. 그리고 나서, Athena를 사용하기 위해 S3 데이터 세트 선택을 해준다.
> ygygtest01 버킷을 선택했다.
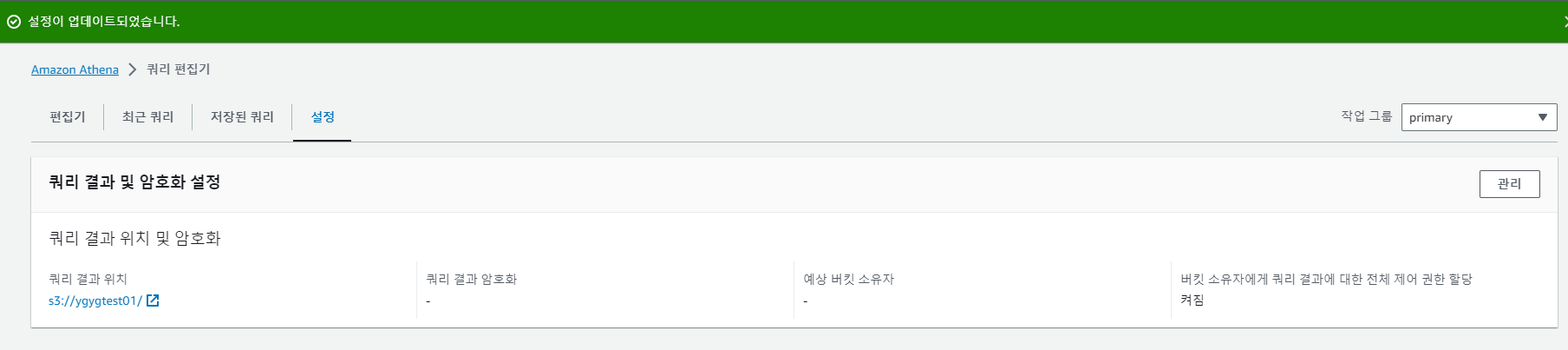
12. 설정을 완료하면 쿼리 결과 위치를 보여 주면서 업데이트 되었다고 위에 표시가 된다.
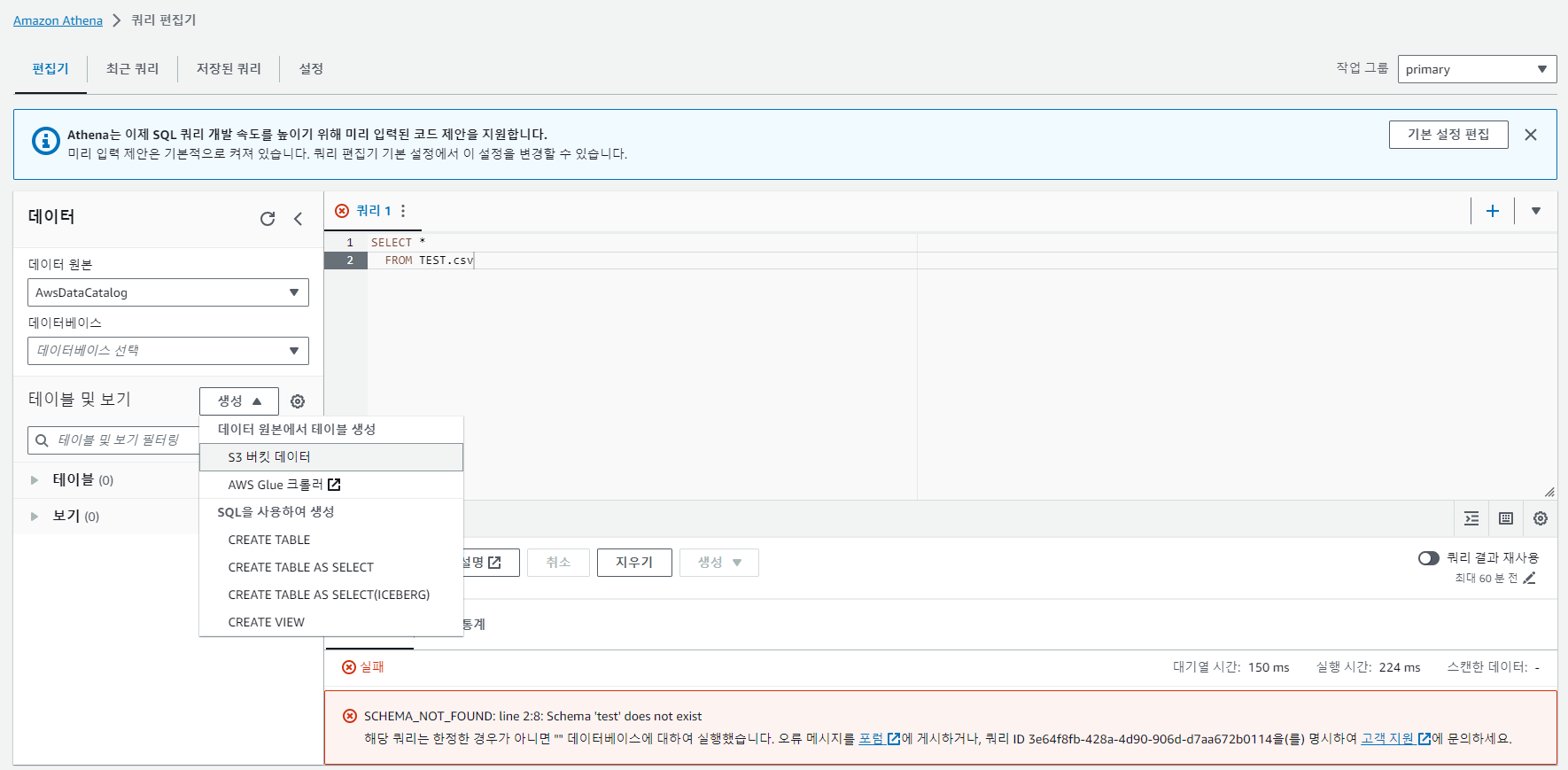
13. 이제 다시 Athena 편집기로 돌아가서 좌측에 [테이블 및 보기] 창에서 생성 버튼을 누르면 데이터 원본에서 테이블 생성 S3 버킷 데이터를 선택한다.
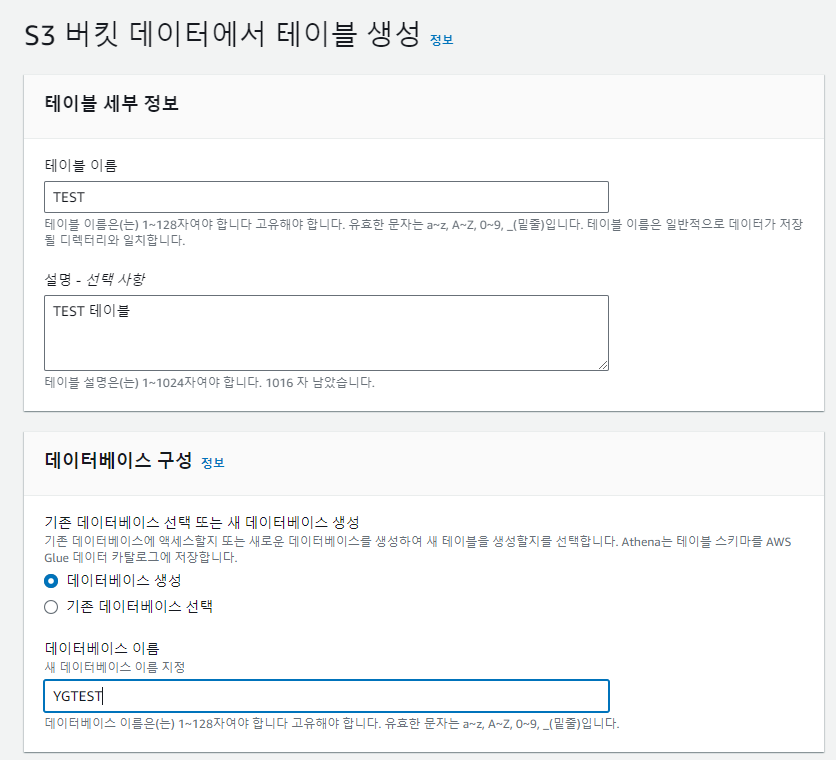
14. S3 버킷 데이터 생성을 누르면 아래와 같이 설정을 할 수 있다.
> 테이블 이름과 설명, 데이터베이스 이름을 입력한다.
15. 데이터 세트의 위치를 설정해 준다.
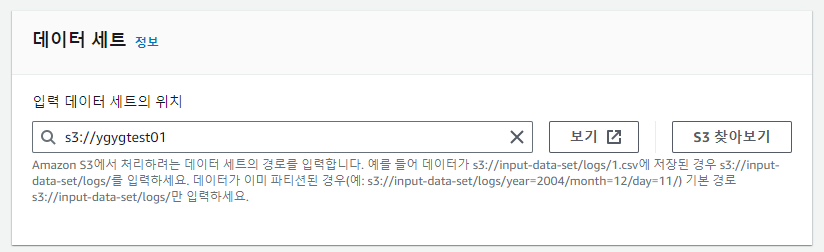
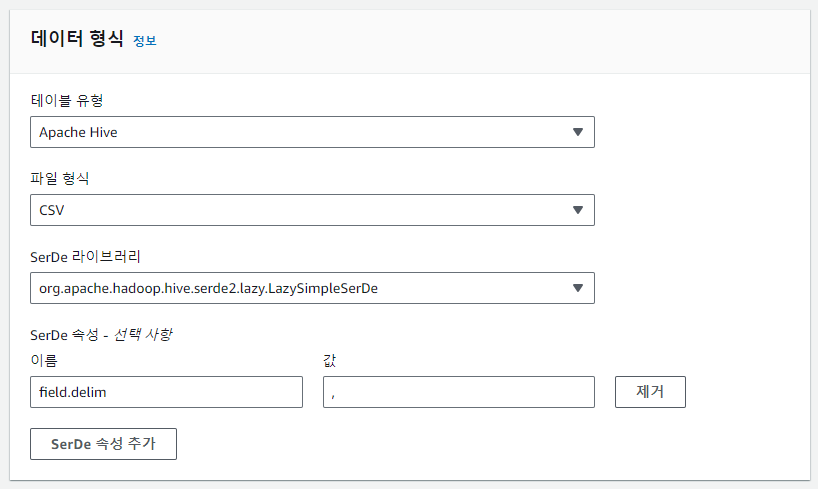
16. 데이터 형식을 설정하면 되는데, csv 파일을 사용할 것이라 아래와 같이 설정한다.
> 테이블 유형 : Apache Hive
> 파일 형식 : CSV
> SerDe 라이브러리 : org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
> SerDe 속성 : Default
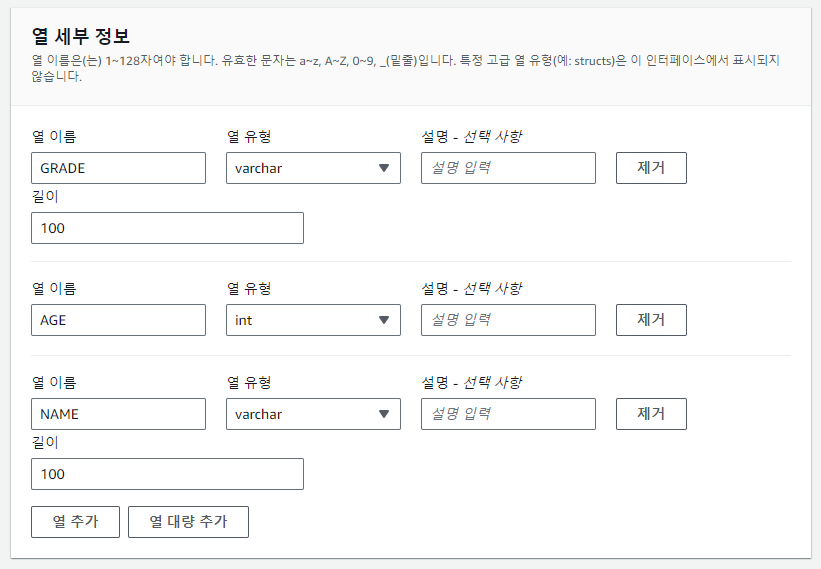
17. 테이블의 컬럼 세부 정보를 입력한다.
> 컬럼 이름, 컬럼 유형, 길이까지 설정하면 된다.
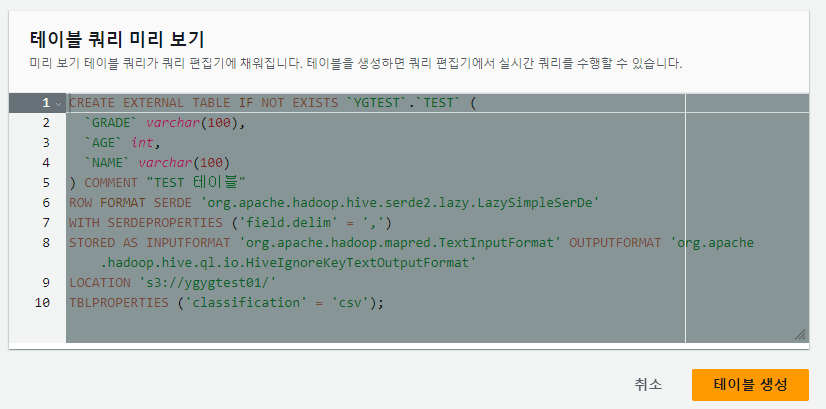
18. 위와 같이, 설정을 완료하면 테이블 쿼리 미리 보기에서 생성 쿼리를 볼 수 있다.
19. 다시 Athena 편집기로 돌아와서 좌측의 데이터 창을 보면 데이터베이스를 설정하고, 아래의 테이블을 보면 test라는 테이블이 만들어 진 것을 확인할 수 있다.
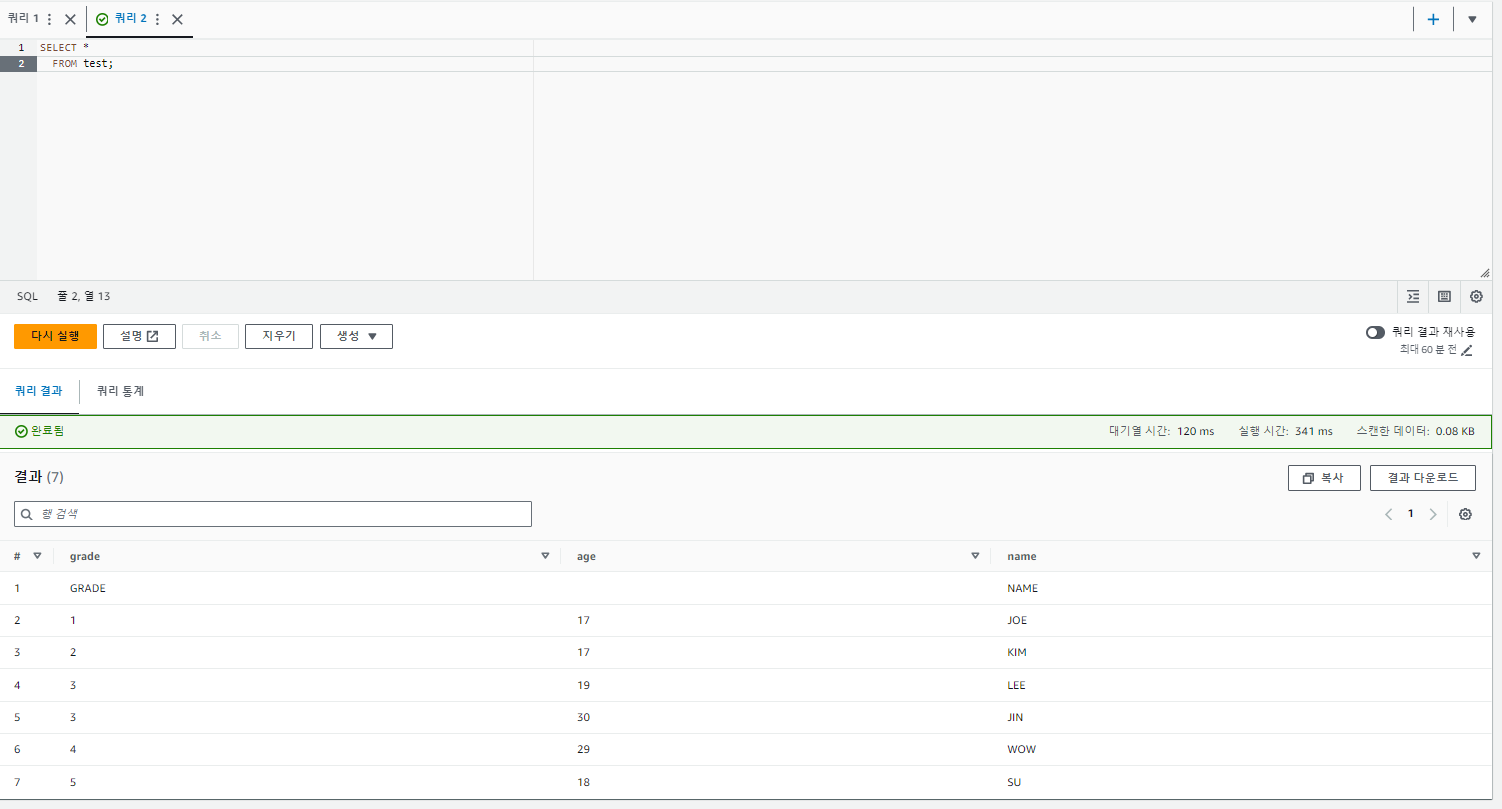
20. 조회 쿼리를 실행하면 아래와 같이 해당 결과 값을 조회할 수 있다.
21. 그리고 나서, 우리가 위에서 조회를 했었을 때 그 결과를 버킷의 특정 위치에 저장한다고 했었으니 확인을 하면 아래와 같이 Unsaved 폴더가 생긴 것을 확인할 수 있다.
> 조회에 대한 결과 값은 연도/월/일 분류 별로 나눠져서 저장이 된다.
> 또한 우측 상단에 다운로드 버튼으로 해당 CSV 파일을 다운로드하여 볼 수 있다.


여기까지가 AWS Athena 서비스 구축 및 예제다.
물론, EC2에서도 S3에 연동하여 사용할 수 있다. 이것에 대한 내용은 다음에 다루도록 하겠다.
참고
https://aws.amazon.com/ko/blogs/korea/amazon-athena-sql-compatible-query-series/
Amazon Athena 초간단 사용기 | Amazon Web Services
지난 2016년 11월 28일부터 12월 2일에 걸쳐 개최된 글로벌 컨퍼런스 AWS re:Invent 2016에서는 20여개가 넘는 신규 기능 및 서비스가 발표되었습니다. 크게 나눠 보았을때 기존 서비스에 추가된 기능(새
aws.amazon.com
'IT > AWS' 카테고리의 다른 글
| [AWS] AWS CloudTrail 생성하는 방법 (0) | 2024.02.05 |
|---|---|
| [AWS] AWS IAM 계정 비밀번호 초기화하는 방법 (0) | 2024.02.01 |
| [AWS] AWS Organizations란?(GetCostAndUsage에 대한 권한이 없습니다.) (0) | 2024.02.01 |
| [AWS] AWS IAM 유저 생성 방법 (0) | 2024.01.30 |
| [AWS] AWS ECR(Amazon Elastic Container Registry) 구축하기 (0) | 2023.11.06 |
| [AWS] AWS S3(Simple Storage Service) 버킷 생성하기 (0) | 2023.11.03 |
| [AWS] AWS 가상머신 EC2 구축하기 (0) | 2023.11.03 |
| [AWS] AWS 계정 생성하기 (0) | 2023.11.03 |








최근댓글