
반응형
matplotlib에서 scatter 그래프를 그렸더니 아래와 같이 그래프에서 2차원 좌표(X, Y)를 그렸을 때 x축의 ticks 값이 정렬이 제대로 되지 않아 뒤죽박죽이 되었다. 그러다 보니, 데이터가 많을 경우에는 x축의 값이 더 추가가 되어 그래프 결과가 이상하게 나온다.
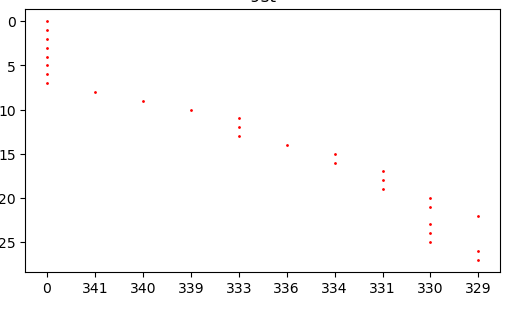
위의 그래프를 보면 0에서 시작했는데, 최소값인 329가 맨 뒤에 나와 있고, 최대값인 341이 맨 앞에 있고, 중간에 값들이 정렬이 되어 있지 않다.
# 그래프 그리기 1차 ~ 28차
plt.figure(figsize=(10,10))
plt.xticks(np.arange(0, 4000, 200))
plt.yticks(np.arange(0, 4000, 200))
# x_list = []
# y_list = []
for object_number in range(len(origin_data.index)) :
# for object_number in range(2) :
row_data = origin_data.loc[object]
x_list = []
y_list = []
# object_number 수에 따른 1차부터 28차 데이터 가져오기 X, Y 좌표
for idx in range(len(origin_data.index)) :
x, y = row_data[idx].split(',')
if x == '0' or y == '0' :
continue
else :
x_list.append(x)
y_list.append(y)
plt.scatter(x_list, y_list, s = 20)
# plt.legend(loc = 'lower left')
plt.show()
위의 코드가 그래프를 그리기 위한 코드인데, 위의 코드를 실행하면 규칙적으로 보여야 하는 좌표 데이터들이 약간의 노이즈가 있는 선형 그래프로 나타났다.
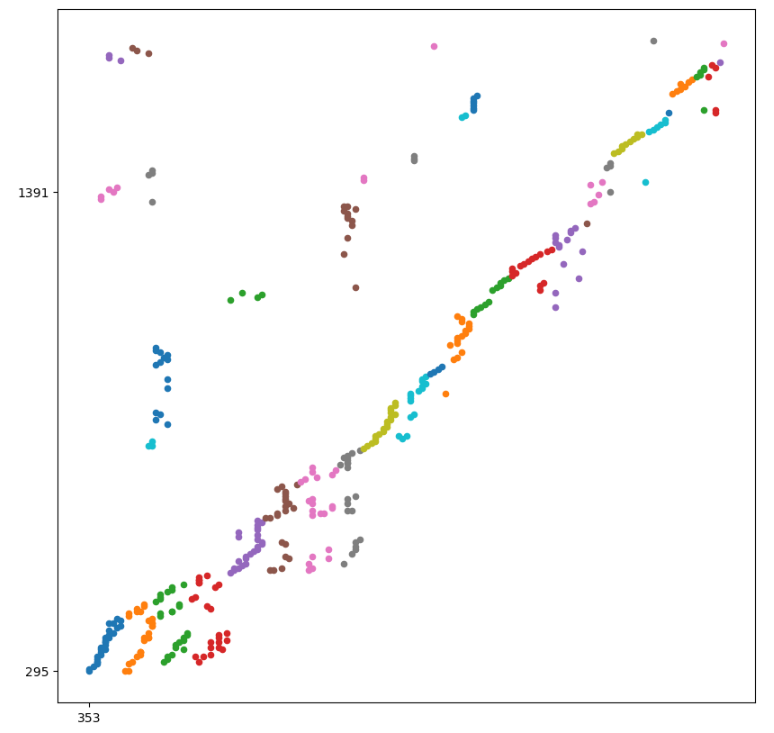
이 데이터를 보면 아무리 생각해도 우리가 육안으로 보고 예상할 수 있는 시각화 그래프가 아닌 것을 확인할 수 있었고 코드의 문제점을 찾아봤다.
for object_number in range(len(origin_data.index)) :
# for object_number in range(2) :
row_data = origin_data.loc[object]
x_list = []
y_list = []
# object_number 수에 따른 1차부터 28차 데이터 가져오기 X, Y 좌표
for idx in range(len(origin_data.index)) :
x, y = row_data[idx].split(',')
if x == '0' or y == '0' :
continue
else :
x_list.append(x)
y_list.append(y)
plt.scatter(x_list, y_list, s = 20)
위의 CSV 파일에서 데이터를 가져와서 쉼표를 기준으로 split을 할 경우, x와 y의 타입은 문자열이 된다. 그래서, 이 x와 y를 리스트에 담을 때 int로 캐스팅해서 넣어봤는데, 이게 원이이었다.
문자열로 scatter 그래프를 그릴 경우, 위의 그래프와 같이 이상하게 나오는데, int형으로 그리면 정상적으로 나온다.
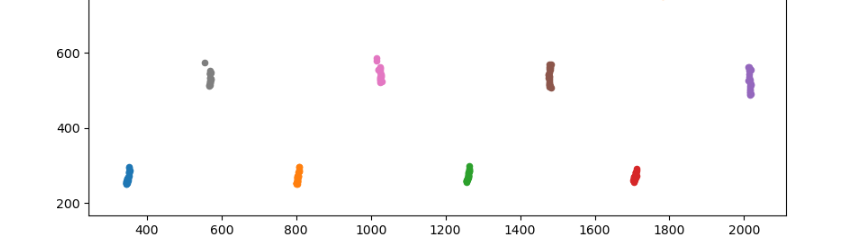
위의 그래프를 봐도 정상적으로 xticks의 범위 내에 잘 나온다.
결론
scatter 그래프를 그릴 때, x축과 y축의 데이터는 int형으로 그려야 한다. 단 예외 케이스는 있으니 무조건 int형으로 하는 것은 한 번 생각하고 해야 한다.
반응형
'Language > Python' 카테고리의 다른 글
| [Python] 파이썬(Python) pip 패키지 목록 requirements.txt 생성 및 실행하는 방법 (0) | 2024.08.14 |
|---|---|
| [Python] Python OpenCV를 사용하여 이미지 밝기 조절하기 (0) | 2024.06.27 |
| [Python] 파이썬 loggging 사용법 및 예제 (0) | 2024.06.26 |
| [Python] 파이썬 List to Str로 변환하는 방법 (1) | 2024.06.03 |
| [Python] 파이썬 데이터 프레임 내 특정 데이터 replace하는 방법 (0) | 2024.05.21 |
| [Python] 파이썬 NaN 다른 문자열로 처리하는 방법 (0) | 2024.05.20 |
| [Python/pygame] pygame.event.get() QUIT에 대한 정리 (0) | 2024.03.21 |
| stat: path should be string, bytes, os.PathLike or integer, not list 문제 해결 방법 (0) | 2024.02.28 |








최근댓글